Apache Hadoop & Spark ビッグデータプログラミング入門 ビッグデータの加工や機械学習のためのプログラミングガイド
- ダウンロード商品電子書籍(PDF版)¥ 1,500
- ダウンロード商品無料サンプル¥ 0無料ダウンロードApacheHadoopSparkビッグデータプログラミング入門_1.2_無料サンプル.pdf(6.2 MB)ApacheHadoopSparkビッグデータプログラミング入門_1.2_無料サンプル.pdf
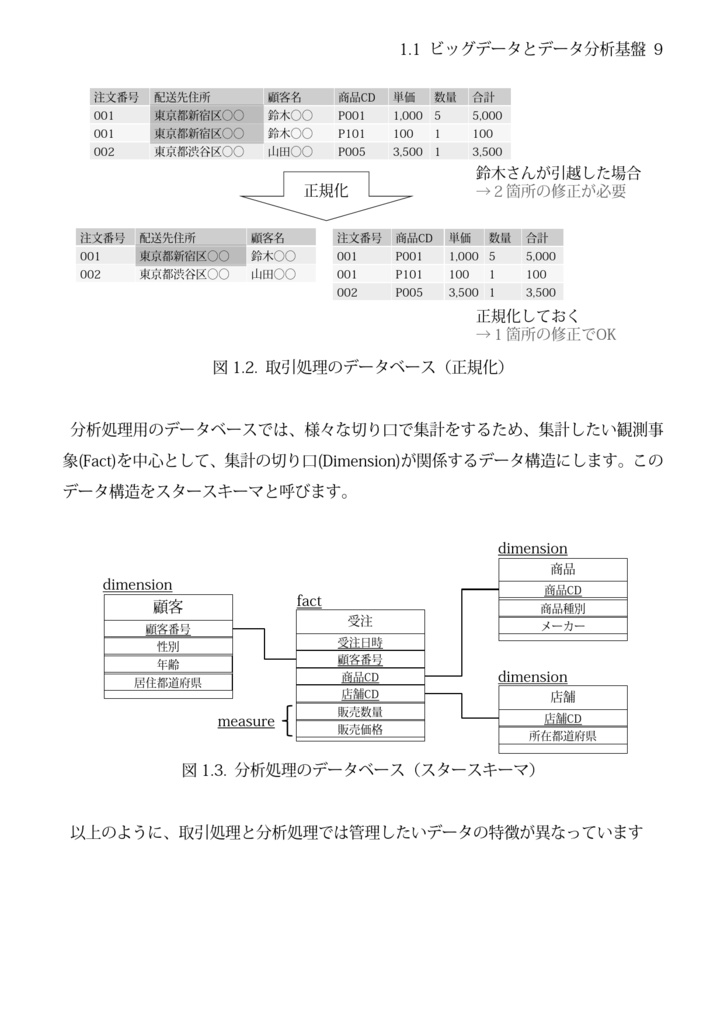
Apache Hadoop & Spark で ビッグデータを対象としたデータ加工及び機械学習の プログラミングを解説した電子書籍です。 ※無料サンプルで、第1章前半までの内容をご覧いただけます。 ■商品の紹介 Apache Hadoop & Spark の概要とデータ分析基盤の中での ビッグデータの位置づけ、 MapReduceやテーブルの結合方法のアルゴリズムを 導入として、Hadoop MapReduce、Hive、SparkSQL、 SparkMLlibを用いた具体的なデータ加工・機械学習の プログラミング方法を説明します。 ■商品情報 種別: 電子書籍(PDF) A5版 70ページ 言語: 日本語 発売日: 2019/04/14 (初版) 技術書典6にて頒布予定 ■目次 第1章 Hadoop & Spark とは 1.1 ビッグデータとデータ分析基盤 1.2 Apache Hadoop 1.3 Apache Spark 1.4 MapReduceアルゴリズム 1.5 MapReduceによるテーブルの結合 第2章 Hadoop & Spark開発環境の構築 2.1 Hadoopのセットアップ 2.2 Hiveのセットアップ 2.3 Sparkのセットアップ 第3章 Hadoop MapReduce 3.1 WordCountサンプル 3.2 MapReduceプログラムの理解 3.3 Hadoopクラスタでの実行 第4章 Apache Hive 4.1 Hiveクエリの実行 4.2 Hiveによるファイルの参照と出力 第5章 Spark SQL 5.1 SparkSQLクエリの実行 5.2 pysparkでのクエリ実行 5.3 チューニングのヒント 第6章 Spark MLlib 6.1 機械学習とは 6.2 Spark MLlibを利用した機械学習 6.3 ハイパーパラメータの探索 ■著者紹介 三上威 (データエンジニア、データサイエンティスト) 略歴: 甲南大学理学部にて応用数学を学んだ後、 NECソフトウェア神戸、ディー・エヌ・エーにて、 システムエンジニア・データマイニングエンジニア。 フリーランスのITエンジニアとして独立後、 アーリース情報技術株式会社を設立。現在、同社社長。